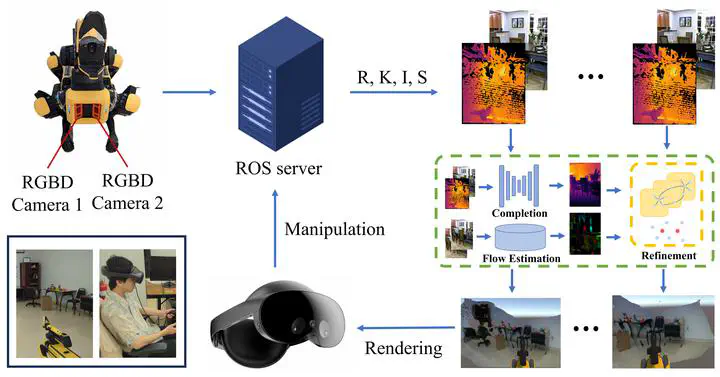
Real-Time Temporally Consistent Depth Completion for VR-Teleoperated Robots
High-quality visual perception is essential for precise control and interaction in VR-teleoperated robotics. Existing systems are often challenged by sparse, noisy inputs and high latency, emphasizing the need for real-time, temporally consistent, and dense point cloud reconstruction.
[Unity Repo] [Model Repo] [Abstract]
Overview
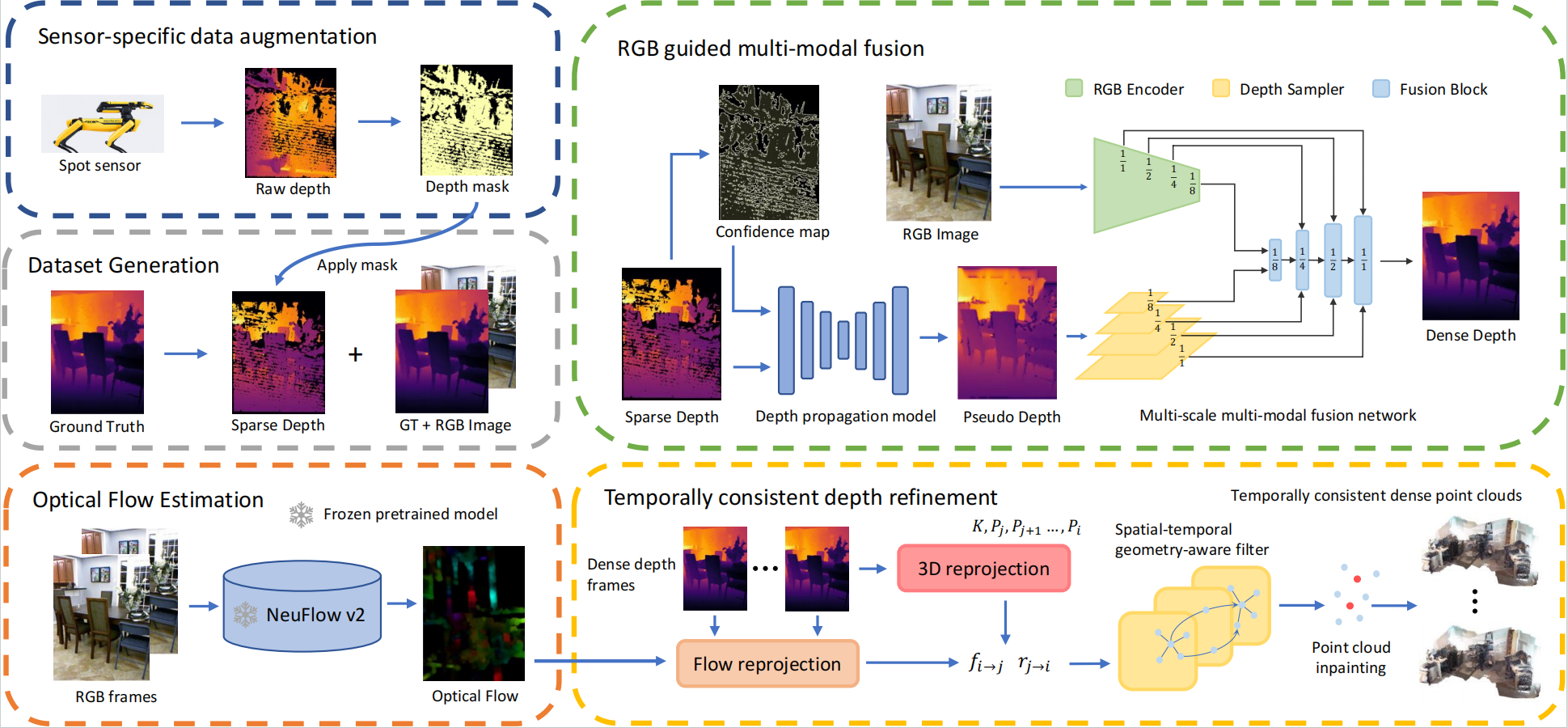
In this project, we present a real-time depth completion and point cloud reconstruction system specifically designed for VR-teleoperated spot robots. We employ an algebraically-constrained, normalized CNN to propagate depth and confidence through multi-modal fusion within a multi-scale network regulated by a gradient matching loss.
Additionally, we implement a spatial-temporal geometry-aware filter that leverages online optical flow and pose estimation to ensure temporally consistent point cloud reconstruction.
This system achieves a rendering speed of 40 FPS, enhancing the visual quality and teleoperation experience.
Demo
VR Teleoperation
Point Cloud Demo
Real-time depth completion and point cloud reconstruction
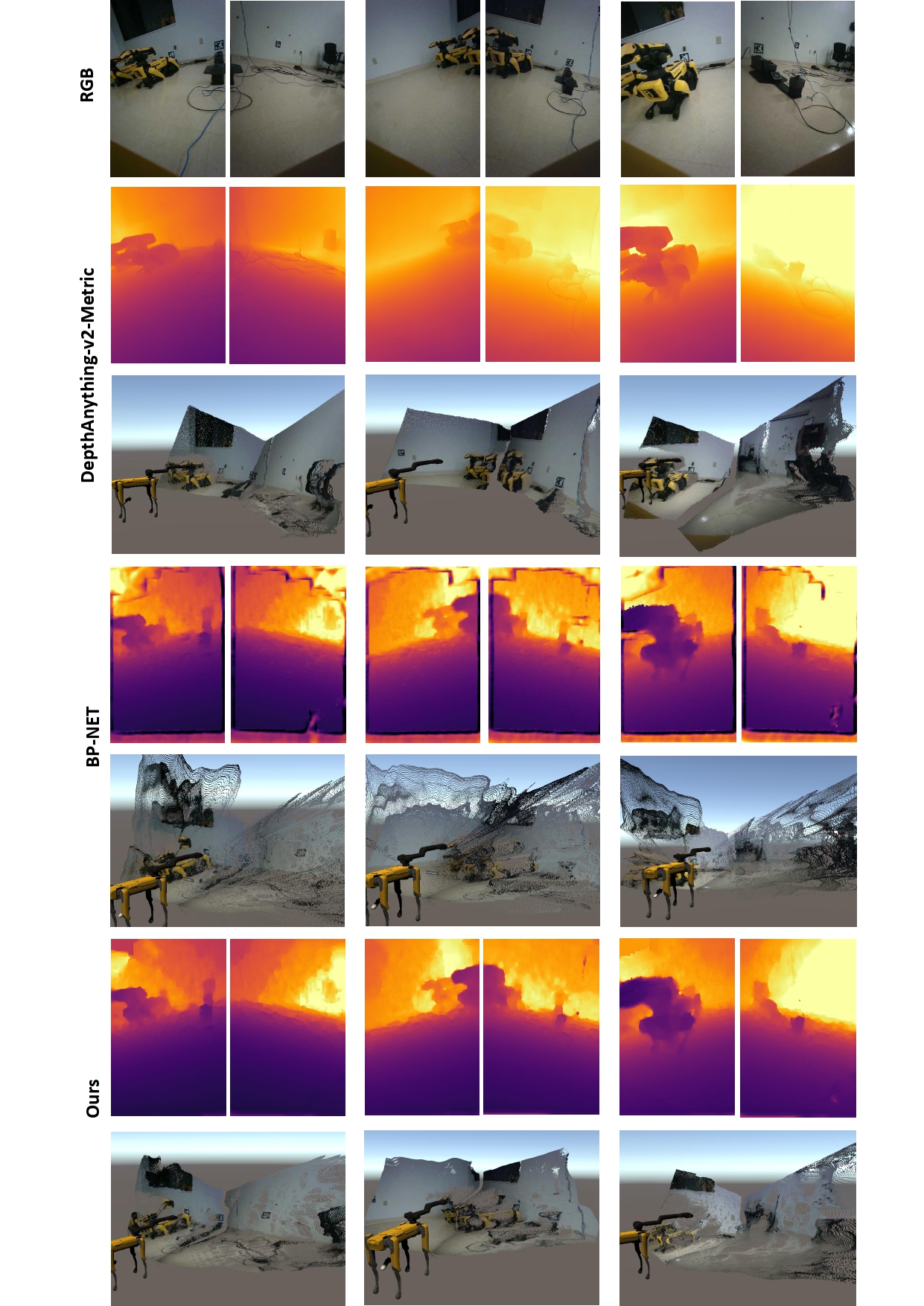
Qualitative Comparison
Depth Completion

Consistent Point Cloud
The top row shows the final rendering results of the Spot moving through the dynamic scene, the middle row shows the result after frame averaging, and the last row shows the result after applying temporally consistent point cloud denoising. We can observe that the geometry of the chair is preserved when the Spot is moving.

More Results
Depth Completion Video
Unguided propagation model + RGB guided multi-scale multi-modal fusion
Left Camera: Sparse Depth
Right Camera: Depth completion Result
Point Cloud Comparison
The top row shows the input RGB images, followed by depth maps and 3D reconstructions from DepthAnything-v2-Metric, BP-NET, and Ours.
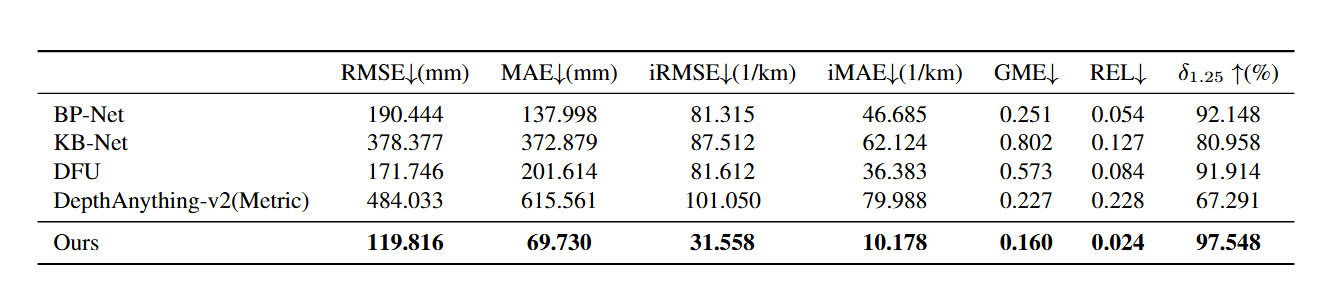
Quantitative Comparison
We evaluate the quantitative performance of five models using the dataset collected by the robot.
Chengfan Li
He once lost a diamond cuff-link in the wide blue sea.